es集群在数据急速增长之后加了一批新机器之后,开始频繁出现linux宕机,无法登录的问题,期间还能收到机器old过高报警,但是等事后反应古来,机器都已经无法登录,也就没办法找回现场了。
在找运维重启完机器,等到一台机器问题复现之后,才发现问题到底处在哪了。
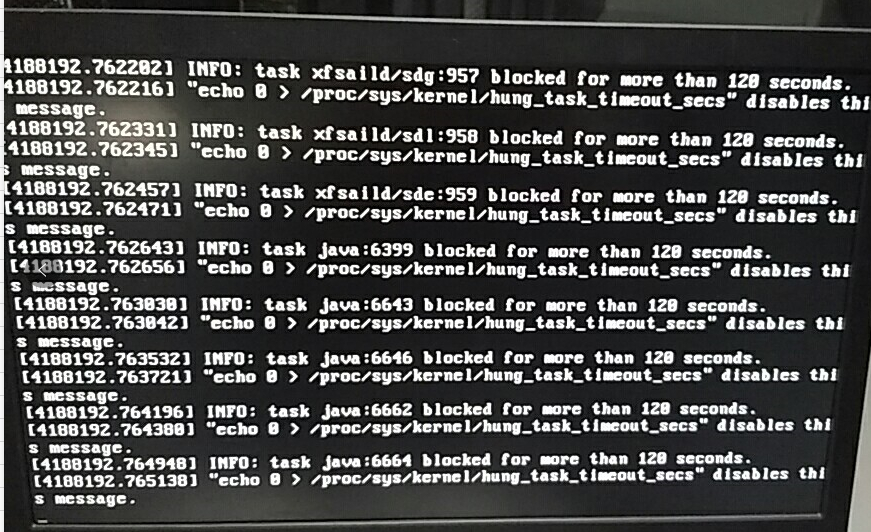
宕机信息
xfsaild 是文件系统的进程,而这批机器使用的FS确实是XFS,根据这个关键字,查到一个相关的信息是 https://elasticsearch.cn/question/1735 ,其中提到的两个点
- NUMA导致内存分配影响
- XFS和es可能不兼容(这个是没有确认的)
但是,机器的NUMA本身就是关闭状态。XFS方面,集群有另外一批稳定运行了一年的机器同样也是XFS,所以可以排除XFS问题。
所以这两个点都被排除。
而在机器宕机之前会出现一次load高的情况,查询cpu占用并不高。因为xfs相关进程出现过,那么首先就怀疑到了磁盘上。
使用iostat -x 1 100之后发现了真相
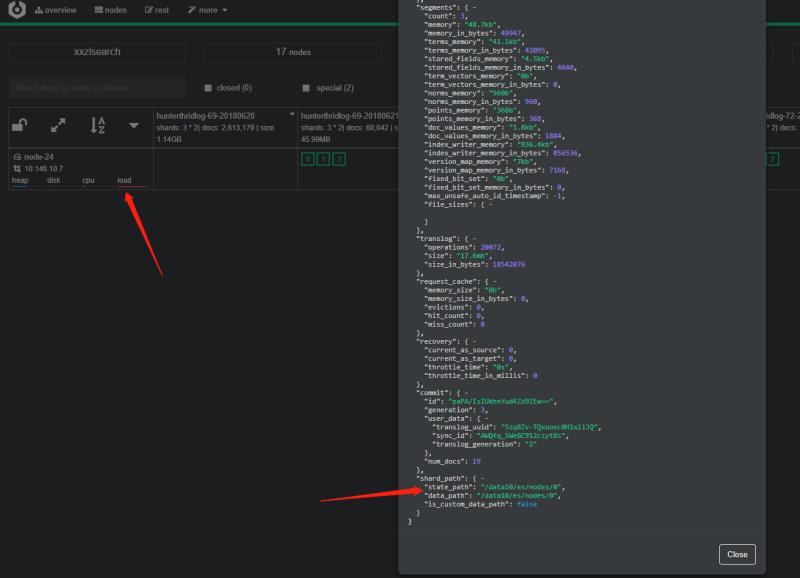
新机器有12块硬盘,而es的disk-base allocation 策略会将shard分配到占用最低的磁盘上,从而导致节点之间的压力不平衡。
而在最闲磁盘上分配了大量shard之后,写入都会集中在这个shard上,从而导致iowait增大,整体需要排队的资源变大,当io操作等待时间超过120s,linux开始宕机。
查看 shard分配情况,当天的新shard都分配到 data10 以及 data9 上。
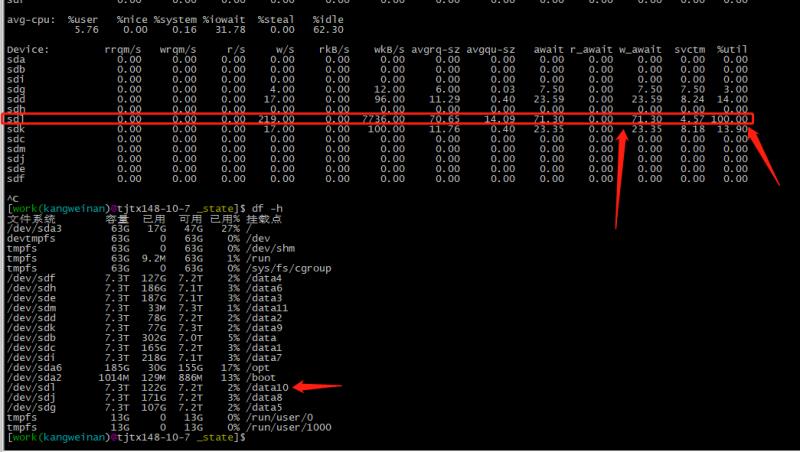
这里是正常写入的情况就已经导致了load达到了32。加上每天凌晨运行的 forcemerge 任务,节点的压力会大大增加。
而且 elasticsearch 对于merge thread 数量设置的默认值也值得商榷。
https://www.elastic.co/guide/en/elasticsearch/reference/6.3/index-modules-merge.html
merge 使用后台线程异步合并segment
The maximum number of threads on a single shard that may be merging at once. Defaults to Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)) which works well for a good solid-state-disk (SSD). If your index is on spinning platter drives instead, decrease this to 1.
合并线程数使用公式 max (1,min(4,cpu/2)) 计算。当时只有当你使用ssd才能使用这个配置来提升merge性能,否则使用传统HDD应该设置成1来保证io操作带来的压力不会过大。
这里是默认用户使用SSD,但却影响了使用HDD的用户。更好的做法是设置 disk.type 选项,如果设置为SSD ,那么启用多线程merge来提供良好的性能和吞吐量;否则使用单线程合并策略。
es这样的io密集程序,最好还是单机部署一个节点,好方便排查问题。否则多个node,公用机器的cpu、io、memory、完全无法判断是哪一部分出现了问题。
改进措施
- 提及IO性能:有钱的上SSD;没钱的拿HDD做raid0凑合着用。
- index级别上设置
index.routing.allocation.total_shards_per_node避免同一个index的多个shard分配到同一个node - 在系统低峰期(凌晨),定时启用rebalance功能平衡节点间数据。需要rebalance的理由如下:1. 数据一般基于时间生成,淘汰之后会造成节点之间的数据不均;2. shard 分配之后写入的数据不均匀,导致节点间数据不平衡。
- 将forcemerge 之类的重操作,和其他操作相隔开。比如1 3 5 凌晨运行 force merge , 2 4 6 凌晨运行rebalance。